Introduction to Data Science Tools and Techniques
Data science is an interdisciplinary academic field that uses statistics, scientific computing, scientific methods, processes, algorithms and systems to extract or extrapolate knowledge and insights from noisy, structured, and unstructured data.
Question : What personality traits give you edge to become data scientist ?
Answer : personality love data , imagination is important aspect , curious about data,
problem solver , quick learner, smart. new methodology and algorithms everyday.
Question : What skills do you need as a data science ?
Answer : statistics , soft skills. R,python language . tools visualization like Microsoft BI tool.
Question : What do you enjoy about being a data scientist ?
Answer : problem solving take complicated problems of business user they want to forecast something , how data can improve their business. working with user identify how to provide value using data.
Question : Advice give to new data scientists ?
Answer : Start playing with data ,don't wait for a job, various data sets available just play with it, take part in competition . writes blogs. join community. methodology learn know those which will work.work on project with people inspire you.
Question : What do Data Scientist do ?
Answer : “More generally, a data scientist is someone who knows how to extract meaning from and interpret data, which requires both tools and methods from statistics and machine learning, as well as being human. She spends a lot of time in the process of collecting, cleaning, and munging data, because data is never clean.
Question : Difference Between Data Science and Data Mining ?
Answer : Data Mining Refers to the science of collecting all the past data and then searching for patterns in this data,The ultimate goal of data mining is prediction. Data Science is an umbrella that contain many other fields like Machine learning, Data Mining, big Data, statistics, Data visualization,data analytics.
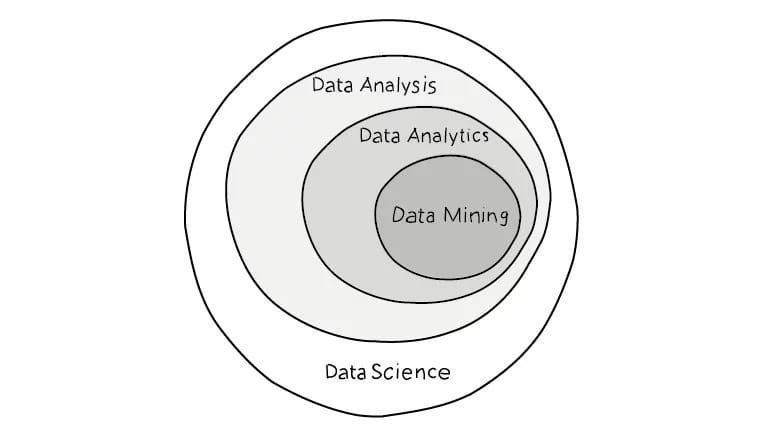
Question : Difference between Machine Learning and Data science ?
Answer :Because data science is a broad term for multiple disciplines, machine learning fits
within data science. Machine learning is a subset of artificial intelligence in the field of computer science that often uses statistical techniques to give computers the ability to "learn" with data, without being explicitly programmed. Data mining use machine learning algorithms to predict data.
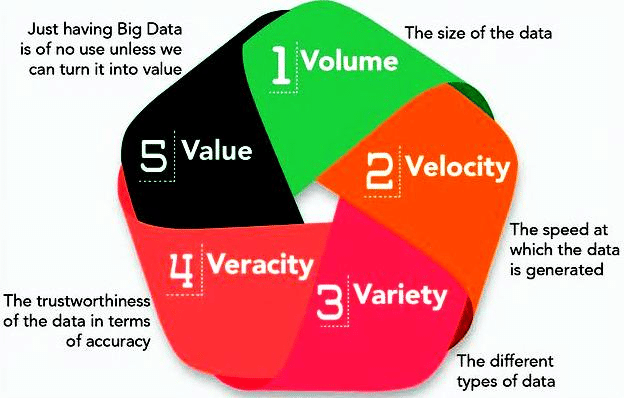
Big Data :
Big Data is a phrase used to mean a massive volume of both structured and unstructured data that is so large it is difficult to process using traditional database and software techniques.
Factors that influence on big data are following.
Application of Data Science
By analyzing the data sets and getting meaningful information is necessary in many fields like medical(prevent diseases) , Military , Banks etc.
Data Science Process
1. Setting Research Goal
Why this problem is important ? how i will tackle or achieve my target ?
Involve domain expert so that you can best analyse the problem and design path how you will achieve your target. Because project scope is better defined if you take help of domain experts or seniors one. Because understanding business goals and context is essentials. Project scoping and project charter is design in this stage.
2. Retrieve Data
Collection of data , mostly internally data is available but it can be distributed in many departments of an organization , there may be confidentiality issues. To manage such kind of conflicts and dealing with people 80% of time of data scientists spend their time. So being a data scientist it’s a big challenge for you manage such kind of conflicts.
If data not available then you can move to alternative sources external resources
Ww.kaggle.com , Datasets available
From other similar organization
UCI machine learning repository
3. Data Preparation
Data Cleansing

Error from data entry: Human mistakes
Impossible values : like age in -1
Outlier : data does not follow normal trends or pattern and seems different in data set. OR an outlier is an observation point that is distant from other observations Depends on the important of outlier we take decision whether to keep those record or exclude it .
Missing values : you can fill missing records if its integer then you can choose median,mean etc but if its string then you can choose mode. You can impute static values and null but its not recommended.
you can perform cleansing using python pandas as well
4. Data Transformation
Exploratory Data Analysis
Some error after data preparation still undetected but it can be detected or found during exploratory data analysis phase.
Histogram , graph etc show data analysis
5. Building the Model
This steps involve machine learning , regression, classification, clustering etc.
Which model is better for your case , as you analyse the data , plot it in exploratory data analysis.
Factors to be consider which model to choose and train your data
Constraints like production environment should be consider when choosing a model/machine learning algo.
If model is time dependant then maintenance and updation is required otherwise after some year it will predict false results. Like model for stock exchange . choose model which need less maintenance.
6. Presentation and automation
After training our model now it’s time to presents the results , soft skills matter a lot .
mostly used tools for data scientist Jupyter Notebook, Tableau,Hadoop,git,TensorFlow and PyTorch,Docker,RStudio,python etc
but for choosing the best tools depends on your expertise as well, For example, if you choose Python as your primary language, explore the libraries and frameworks available for data manipulation (NumPy, pandas), machine learning (scikit-learn, TensorFlow), and data visualization (Matplotlib, Seaborn).
Dataset Online sources
There are several websites where you can find datasets for data science projects and examples.
UCI Machine Learning Repository: https://archive.ics.uci.edu/datasets
UCI offers a vast collection of datasets that cover various domains, including classification, regression, clustering, and more. These datasets are well-documented and suitable for machine learning research and practice.
Kaggle : https://www.kaggle.com/datasets
Data.gov : https://data.gov/
Data.gov is the U.S. government's open data portal, offering a vast collection of datasets related to government agencies and public information. It covers topics such as health, education, environment, and more.
Statista: https://www.statista.com
Statista offers statistical data and infographics on a wide range of subjects, including market research, demographics, and industry reports.
Google Dataset Search:https://datasetsearch.research.google.com